















Is There a More Efficient Way To Learn Vocabulary?
In most grammar classes and textbooks, you learn words in groups. You might learn about animals on one day and fruits the next. This is comfortable, both for language teachers and students. Your teacher gets to have a clear lesson plan (today is about numbers), and you get to accomplish something (today, I learned the numbers!).
But is this the most efficient way to learn vocabulary?

If you look at the research on vocabulary acquisition, you’ll find a surprising result: weirdly enough, learning groups of similar words (apple, pear, banana) is significantly harder to learn. You’ll be much better off if you either learn words in unrelated groups (apple, dog, red) or in groups that form stories (apple, sweet, to eat).
Interference
The research on this topic revolves around the concept of interference. Here’s the idea:
Suppose you learn a bunch of fruit names: une pomme (apple), une poire (pear), une pêche (peach), etc. A few days later, you try to recall one of those words.

Upon seeing the picture, your brain jumps into action, looking for your word through several possible routes. It’s a fruit! It’s a French word I learned a few days ago! It starts with a P!
And because you happened to learn three French fruits that start with the letter P (and all on the same day), you’re kind of screwed. Memories compete. When you try to recall your word, your three French fruits get into a kind of mental tug-of-war, while you try to figure out which one seems the most apple-like. As a result, you’ll have a harder time remembering pomme, and even if you do remember, you’ll take much longer to find it.
That’s not even the end of the story. While you’re having this mental fight, you’ve probably just made the situation a little worse for next time. Every time you think of two things at once, they interconnect. So if you’re busy thinking about pommes, poires and pêches, and you’re not particularly sure which one’s which, then you’re drawing those three fruits together into a jumbled group of “Fairly confusing French fruits that start with the letter P.” You’ll be more likely to remember all three fruits the next time you try to retrieve the word for pear or peach.
I’ve run into this problem quite a bit on my own, especially in French, where I learned a lot of similar words at the same time. I still have problems remembering wither sept is 6 or 7, or whether jaune is yellow or green.
The defense against interference is to make similar words as different as possible. And since you can’t go into the French language and change pomme and poire so that they don’t start with the same letters, your only real ability to do this involves learning these words at different times.
The Research
The concept of interference has been researched in a lot of different contexts, and I’ve linked five related studies at the end of this article, if you’d like to read more.
One of the first studies (Waring 1997) gave test subjects a group of 3-6 words and their “translations” into a fake foreign language (apple = tisahl, pear = nugaw, etc.), and recorded how long it took each subject to memorize the translations. Half of the subjects got a group of closely related words (jacket, shirt, sweater), and half got unrelated words (frog, car, rain). The researchers would quiz subjects (what’s the word for “jacket”?) until they could remember every new translation within 3 seconds (‘jacket’ is……iddek!), and recorded the number of times they needed to repeat the tests until a subject successfully memorized a word. These are their results:
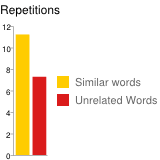
Similar words took more than 35% longer to learn, at 11.3 repetitions for a group of similar words, compared to 7.2 repetitions for a group of unrelated words. This isn’t particularly efficient.
Still, time isn’t everything. What about retention? Once you memorize a group of similar or unrelated words, how well do they stick?
In a 2008 study, researchers tested these ideas in a school, teaching Turkish kids 40 unrelated English words (peg, key, rat, sun) and 40 related words (20 foods and 20 animals) in a classroom setting, and testing them afterwards on how well they could match English words and pictures. They tested them immediately after each lesson and again 1 week later. In both cases, the kids had a harder time remembering similar words:
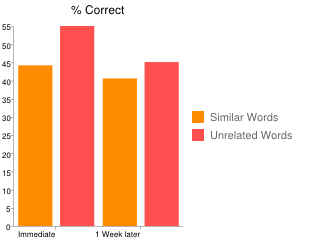
And they took longer to finish every similar-word quiz, taking an average of 5.8 minutes to finish, compared to 4.9 minutes for unrelated-word quizzes.
Other ways to learn words
When you go by the numbers, learning similar words at the same time is a fairly crappy idea, even if it feels a bit more comfortable. So what are the alternatives?
In most studies, the alternative to word groups involved learning a jumble of totally unrelated words, and that works quite well. If you’ve perused through this site, you’ve probably run across my Base Vocabulary List for Any Language, which is currently arranged in typical word groups (animals, professions, etc.)
Based upon the research, I started playing around with the idea of an alphabetical list. Normally, an alphabetical list would solve the similar word problem at the expense of adding a new problem: the words would all sound similar. But if you start with an alphabetical list in English and then translate it into your target language, you basically create a randomly ordered list anyways. So I put my English word list in alphabetical order, translated it into Hungarian, and learned that list. In practice, I found that memorizing words was much easier. I stopped getting my greens confused with my yellows (although I still get six confused with seven; I didn’t follow my own advice when it came to numbers, and Hungarian’s six and seven – hat and hét – are extremely similar looking).
Alphabetical lists are also a lot easier to use; I could just skim through my Lonely Planet Phrasebook, circle my A-words, then circle my B-words, and after 30 minutes, I had good translations for every word in my list. So in the near future (probably next week), I’ll release a new version of that list (with an extra couple hundred words) in alphabetical order, so that it’s easier to use and easier to memorize.
But alphabetical and random orders aren’t the only options. In one of the earliest studies, researchers tried out groups of words that shared the same theme. These are words that tell a story – sweater, changing room, try on, cash register, wool, navy blue, striped – rather than words that fit in the same category, like sweater, shirt, jacket, and coat. They’re related words, rather than similar words, and there’s a huge difference between them.
Learning related words – words that form stories – worked even better than totally random words, although the effect was relatively mild. Subjects needed ~10% fewer repetitions to learn a group of words like “frog, hop, slimy, pond, croak, and green,” compared with “cloud, erase, social, office, lose, and risky“:
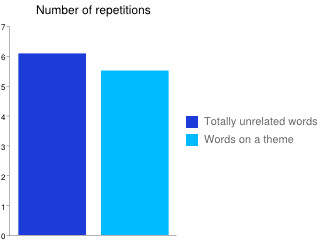
Maybe in the future, I can create a frequency list that’s arranged in little story-like clusters. That’d be pretty neat to have, although it would need to be professionally translated first, since it’s kind of a pain in the butt to translate a list that isn’t in alphabetical order. I’ll probably get around to that eventually, but there’s a way you can give yourself that 10% boost in memorization speed right now: by learning chains of words through Google Images.
Chaining words together to make them easier to learn
I’ve talked about learning words through Google Images a few times so far. The basic idea is that you search for a word like “dernier” (last) and get results like these:
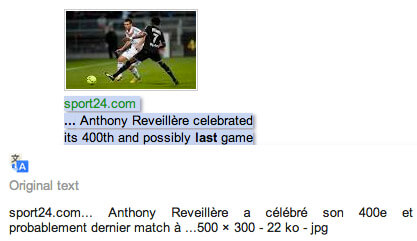
Then you use the French sentence and the picture to learn your word.
Dernier is the word that fits into “Anthony Reveillère a célébré son 400e et probablement __ match.”
But suppose you didn’t know the word “célébré” or “probablement.” You could use this sentence to learn those words, too. Or you could look up a new story for one of those words, creating a chain of connected stories:
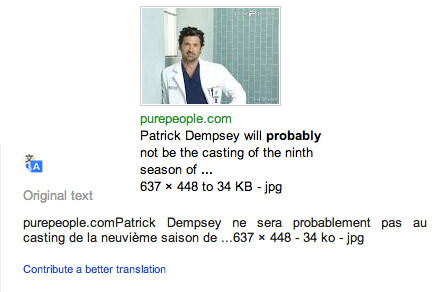
You might then learn “saison” or “neuvième,” either by re-using this story or by adding yet another a new story to your chain.
Through this process, you can learn a long string of related words in the context of interconnected stories.
They’ll be faster to memorize and easier to retain than totally unrelated words, and they’ll be much better than a list of similar words like apple, pear and apricot. I like to use a frequency list to guide my general vocabulary studies, and then whenever I encounter a particularly interesting word, I’ll create a little chain of words and stories. In the process, I learn a lot more vocabulary, get a lot more exposure to a bunch of sentences, and have an easier time remembering all of it.
If you’d like to read more on the topic of interference and vocabulary acquisition, check out these articles. Their introduction sections are often pretty readable:
- Effects on vocabulary acquisition of presenting new words in semantic sets versus semantically unrelated sets (2008)
- Vocabulary acquisition from extensive reading: A case study (2006)
- Semantic category effects in second language word learning (2003)
- The negative effects of learning words in semantic sets: A replication (1997)
- The effects of semantic and thematic clustering on the learning of second language vocabulary (1997)
That’s it!
If you have questions or suggestions, post in the comments section below. If you’d like to get email notification whenever there’s a new post, subscribe to site updates!
Make Your Flashcards Faster
If you want to save yourself ~30-60 minutes of time making your first Anki flashcards, then check out our shop which has a number of resources you can use to speed up the process. There are also other ready-to-use Anki flashcards in various languages that you can check out. Don’t forget that we also have our Fluent Forever mobile app, which doesn’t use Anki, but can be way faster.
[shareaholic app="share_buttons" id="28313910"]